

Large Language Models can be a force multiplier for a multitude of use cases. This post focuses on how to integrate LLMs in the backend.
Introduction
Large Language Models (LLMs) are the newest and coolest kid on the block. Their core
function is to understand and produce text in a manner that closely resembles human cognition.
While the concept of machines processing and producing language isn’t new, the scale and accuracy achieved by recent
LLMs have transformed the discourse around their potential applications.
LLMs trace their origins back a few years.
As computational power and research methodologies advanced, these models expanded in complexity, evolving from simple
text predictors to sophisticated language processors capable of tasks ranging from content creation to code assistance.
One notable advancement in the LLM domain was the release of ChatGPT by OpenAI.
Its widespread availability marked a significant shift in the AI landscape, providing everyone with unprecedented access
to top-tier language processing capabilities. This model and its subsequent iterations have
underscored the significance of LLMs and set the stage for their broader adoption in various industries.
In this article, I will provide
- a brief introduction to the inner workings and key concepts of LLMs, and
- (most important!) get our hands dirty in a step-by-step guide deploying a private LLM.
Inside a LLM
Image generated by Bing Image
At their core, Large Language Models (LLMs) are a form of deep learning, leveraging neural networks to understand and generate text. Let’s look at some basic concepts around them.
Training a model
Training an LLM (or any neural network, for that matter) is akin to teaching a child to recognize patterns.
Over time, with exposure to various examples, the child begins to understand and predict those patterns.
LLMs function in a similar way. Exposed to vast amounts of text data, they learn to recognize patterns in language.
Through this process, they develop an understanding of grammar, context, language use, and even nuances like sarcasm and
humor.
Key concepts
Tokens
In LLMs, language is broken down into units called “tokens”. A token can be as short as one character or as long as one
word. For example, the phrase “LLMs are amazing” might be divided into tokens like ["L", "L", "M", "s", " are",
" amazing"]. Tokens are then mapped to a unique numeric value, like in a dictionary. The numeric value is how the model
“understands” the text.
Model Size
Model size, often denoted in billions of tokens, is the neural network’s capacity. A larger model size means
the LLM has been trained on more tokens, making it potentially more knowledgeable and accurate. However, this also means
more resources are required to operate it.
Context window
The “context window” refers to the amount of recent information (in tokens) the model can consider when generating a
response. For example, if the context window is 10 tokens, the model will only consider the last 10 tokens when
generating a response. A larger context window means the model can consider more information, i.e. have a longer “memory”.
Inference
“Inference” is the process by which the model generates responses or predictions. Once trained, the LLM doesn’t “think”
or “reason” like humans. Instead, it uses its learned patterns to generate the most likely next sequence of tokens based
on the input.1
Temperature
“Temperature” is a parameter used during inference. A higher temperature makes the model’s output more random, whereas
a lower temperature makes it more deterministic. Think of it as adjusting the model’s level of creativity: too high,
and it might produce wild results; too low, and it might be too predictable.
Open- vs closed-source LLMs
In the world of Large Language Models (LLMs), there’s a critical distinction to understand: the difference between open and closed-source implementations. This distinction is not purely about the accessibility of the code but more about the accessibility and distribution of the trained model itself.
The Two Parts: Code and Weights
LLMs essentially have two primary components: the code and the weights. The code is the blueprint, typically a few hundred lines or less, that dictates the architecture and functioning of the neural network. This piece is often open-source and can be viewed, modified, and used by anyone.
However, the real essence (the “secret sauce”) of an LLM lies in its weights.
Think of weights as the accumulated knowledge from the training data. They determine how the model responds to
different inputs.
The Cost and Value Proposition
Training an LLM to achieve these weights at high quality is not trivial; it demands vast computational resources and large datasets, translating to significant costs. For companies like OpenAI and Anthropic, these costs mean that their most advanced models’ weights remain proprietary and behind paywalls. By keeping the models closed-source (and needing pay for their use), they can recoup investment costs and fund future research.
On the other hand, some organizations, like Meta, have taken a different approach by open-sourcing their model weights. This democratizes access to advanced AI capabilities, allowing community-driven enhancements and applications. However, it’s essential to understand that even with open-sourced weights, using the model at scale will still require significant computational resources to perform inference.
Chatting with a Model
Conversing with LLMs is a very natural form of interaction, as through the conversation, the models are able to generate contextually accurate replies.
The Power of Context
Every time you send a chat message to an LLM, it doesn’t just see that message in isolation. Instead, it takes into
account the context, which includes prior messages in the conversation. This context is crucial because it helps the
model maintain a coherent and relevant dialogue. For instance, if you ask the model a question and then follow up with
another related query, the model uses the context of the first question to ensure the second response is consistent and
relevant.
In simple words, the interface resends the entire conversation history to the model every time you send a new
message.2
Building on Inference
While it might seem like the LLM is “chatting”, what’s actually happening is a series of inference operations. Each question (or better, prompt) posed to the LLM triggers an inference. The response generated is the model’s prediction of the most appropriate reply based on its training.
The Importance of History
Remember the “context window” mentioned earlier? It plays a vital role in conversations.
LLMs have a limit to how much previous conversation they can “remember” or
consider when generating a response. If a conversation is too long, older parts of it might fall out of this window.
This is why, in prolonged interactions, an LLM might seem to “forget” earlier parts of the conversation.
With the introduction of basic concepts out of the way, let’s move on to…
Our project
The UI of ChatGPT has become the de-facto standard for interacting with LLMs.
In the ChatGPT setup, the single-page application running in the user’s browser, calls the OpenAI API to generate responses (direct call).
We will build on that and create a backend service that will:
- expose an interface identical to the OpenAI API,
- operate as a proxy to the OpenAI API (e.g. grouping chat operations for a whole team, to reduce token consumption), and
- allow us to transparently switch between OpenAI’s models and our own LLM(s).
From a high level, our prototype will look like the following diagram:
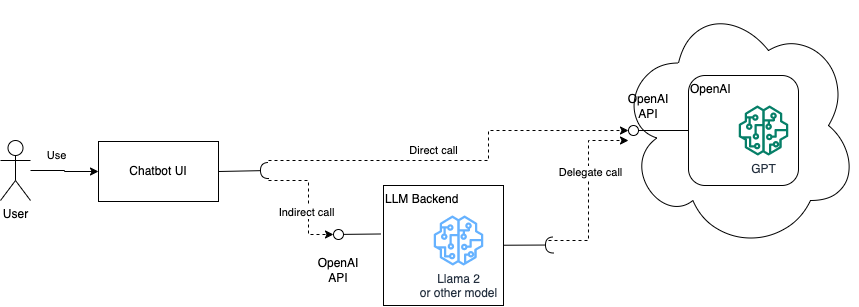
High level design of our prototype
To keep things simple, I will not implement a chat UI from scratch.
Instead, I will fork and use the nice Chatbot UI.
Now that we have a target architecture…
Let’s get coding
The code for this post is split between two repositories:
- chatbot-ui - the UI, forked from the original Chatbot UI, and
- llm-backend - the backend service
As we improve the code in each section below, we will be referring to the corresponding branch (v1, v2, etc).
Clone the code and switch to the appropriate branch to follow along.
v1 - Setup & calling OpenAI
Switch to the v1 branch in both projects and install the dependencies as described in the README. You will also need
to create an OpenAI account and get an API key.
In this initial version, the goal is to create a Python service, which
- emulates the OpenAI API, and
- acts as a pass-through proxy for
chatbot-ui.
The quickest way to achieve this is by using Connexion, a framework to process HTTP requests based on an OpenAPI
definition.
We download the OpenAI API reference and modify the operationId so that Connexion can map to the right
handler. The chat and model controllers are the only one implemented at this point, as simple pass-throughs
to the OpenAI API.
Let’s run the 2 services and see them in action.
From inside the llm-backend directory run OPENAI_KEY_BASE64=<YOUR_OPENAI_API_KEY_IN_BASE64> tilt up. This will
start the service and the UI client in a local K8s cluster.
Then open your browser at http://localhost:3000 to post a chat in the UI client.3
You can monitor the logs of both services in the Tilt UI.

We have a good starting point, time to move to…
v2 - Decomposing the OpenAI API
This version of llm-backend is functionally identical to v1.
The difference lies in us creating an explicit set of model classes to represent the OpenAI Chat API. These will
allow us to plug in our own LLM implementation in the next version.
Feel free to explore the code and run the local tests: make test
Brief pause - Intro to llama.cpp

Photo by Timothy Eberly on Unsplash
Before we move on to the next version, let’s take a brief detour and introduce the LLM implementation we will be using: Meta’s Llama.
The release of Llama’s weights4 sparked a wave of innovation in the LLMs. An
industry-strength model, available for all to experiment with, was not something to ignore.
There is an ever-increasing list of fine-tuned models, all using Llama’s weights as a starting point.
Another innovation was the release of llama.cpp, a port of Llama’s codebase to C++. This allowed the execution of inference on a desktop machine, using a quantised (read memory-compressed) model.
Let’s use llama.cpp offline (or better a Python wrapper over it). We will generate a few responses and see how it performs.
Please note:
- You will need to have several GB of free RAM to follow along.
- Detailed instructions can be found here.
The following one-liner command
- fetches a llama.cpp Python wrapper project,
- compiles it for a Mac GPU, and
- downloads the Vicuna 13 billion token 5bit quantised model (>9Gb in size)5.
1 2 3 4 5 6
cd <somewhere_with_enough_space> git clone https://github.com/fredi-python/llama.cpp.git \ && cd llama.cpp \ && make -j LLAMA_METAL=1 \ && cd models \ && wget -c https://huggingface.co/CRD716/ggml-vicuna-1.1-quantized/resolve/main/ggml-vicuna-13B-1.1-q5_1.bin
With the model downloaded, let’s see it in action. Run the following to start it in interactive mode, then type your prompt. If you downloaded a different model, simply replace the file name.
1
2
3
4
5
6
./main \
-m models/ggml-vicuna-13B-1.1-q5_1.bin \
--repeat_penalty 1.0 \
--color -i \
-r "User:" \
-f prompts/chat-with-vicuna-v1.txt
You will get something like the following output.
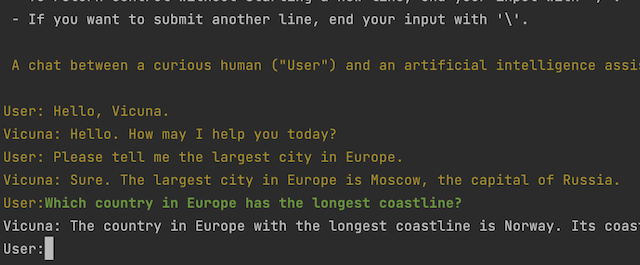
Awesome! 🎉
We are now ready to use our own model in our backend service.
v3 - Integrating with Llama
Let’s switch to branch v3 in both chatbot-ui and
llm-backend.
In this version of the llm-backend code we have:
- the ability to configure a local LLM model via an env. variable,
- updating the models endpoint to inform the frontend on additional models, and
- separate chat controller classes for OpenAI and local Llama processing.
The only (tiny) change we do to chatbot-ui is to add our custom Llama model to the list of options. This will
allow the frontend to instruct the backend to use our local model.
We can run the test suite with
1
OPENAI_API_KEY=<YOUR_OPENAI_KEY> LLAMA_MODEL_FILE=/path/to/local_quantised_file.bin make test
Notice the performance difference between the OpenAI and the Llama tests in the timings printed
at the end of unit test execution. You can experiment with different token batch sizes to see how it affects speed (with
1 being the extreme).
Depending on your machine and the size of the model, the local Llama tests may even timeout. In this case you may want
to try with a (much) smaller model, e.g. Llama2 7Billion 2bit.
Fix the hard-coded model path in the Tiltfile and let’s see it in action, in our local K8s cluster.6
1
`OPENAI_KEY_BASE64=<YOUR_OPENAI_API_KEY_IN_BASE64> tilt up`
We can see that the front-end picks up the new model as an option.

We type our prompt and…

Nothing! Crickets! 🦗
The worker times out on my machine.
Our local K8s cluster is setup without any mounted GPU, so inference takes too long using only the CPU.
Time to bring out the big guns!
v4 - Deploying to a GPU cloud

Photo generated by Bing Image
Since LLM inference is millions upon millions of numeric calculations, using a GPU is the way to go. We will need to make some changes to be able to deploy our service to a GPU cloud.
Let’s switch to branch v4 in 'llm-backend.
We will be using RunPod as our cloud provider7.
Our code is working fine, so the focus is on creating the right Docker image. Namely we need to:
- have a GPU-enabled base image, and
- ensure that llama-cpp is correctly compiled with GPU support.
Using one of TheBloke’s base images and scripts as a guide, we end up with
- a Runpod-specific Dockerfile, and
- a set of scripts to start the image and download a model.
I have built the image and pushed it to Docker Hub (tag v4-cuda), using the command make build-docker.
You can re-use that image in your tests, or feel free to build your own.
We use the image to create a RunPod template. Note the disk sizes, the environment variables (to download a GGML Llama2
model) and the open ports.
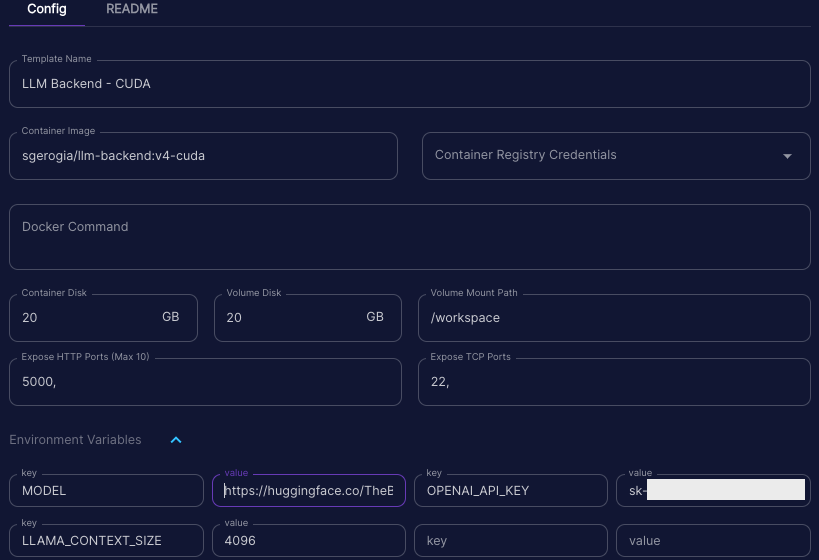
We can then pick from the list of available GPUs and deploy our template.
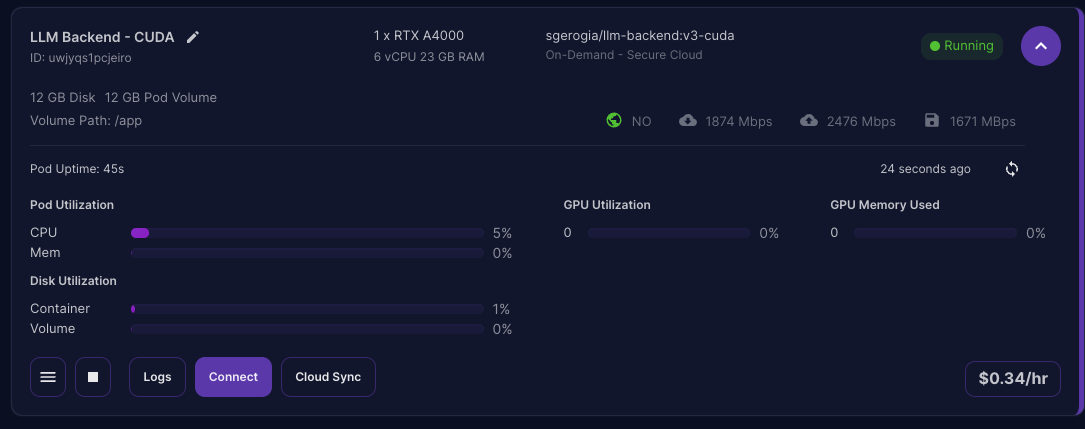
We can monitor the logs from the dashboard…
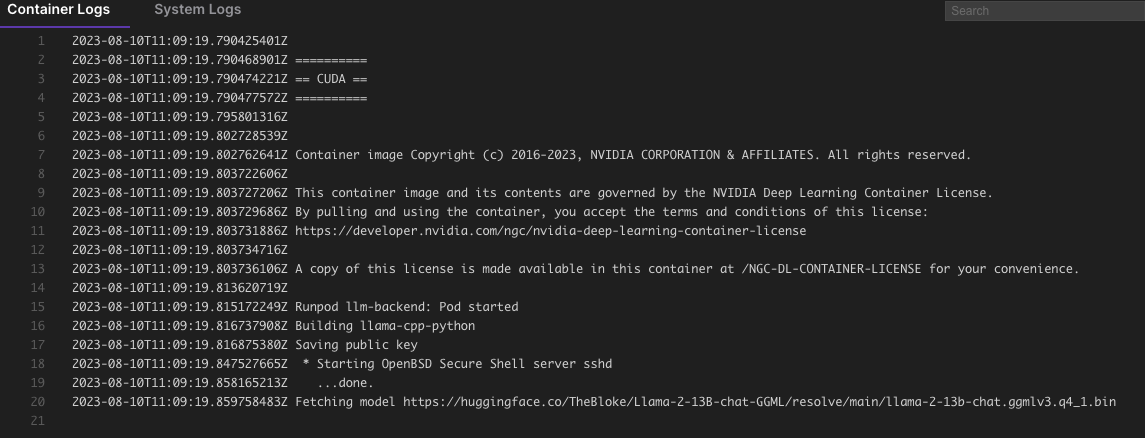
or SSH into the pod.
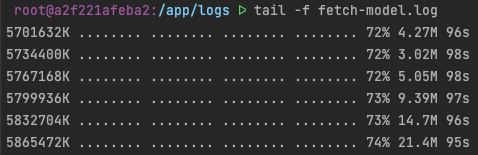
Once the Python server starts, we can launch our local frontend and chat with our Llama model.
The quick-and-dirty way is to “hijack” our local Tiltfile by directly pointing to the remote RunPod host name.
Et voila! 🎇🎉🥂

Performance comparison
If this is your first time using a GPU cloud, you might ask yourself “Which GPU do I choose?”
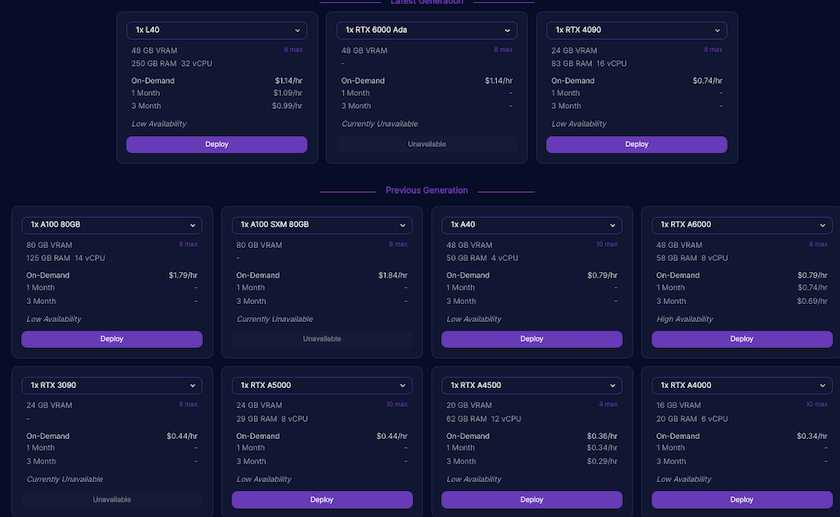
The answer is “It depends”.
Newer (and more expensive) is generally better as you get more compute power and more VRAM. On the other hand, depending
on the application (direct user interaction or batch processing), slower might be more cost-effective.
To make it visual, here are 3 screen captures of the above RunPod template, using the same Llama 2 model, and prompt, running on 3 different GPUs. I also list their associated costs per hour at the time of running this (unscientific) test.

A100 - $1.79/h
A6000 - $0.79/h

L40 - $1.14/h
Of course, the above is not meant to be a benchmark, as it does not take into account network traffic, load on the cloud server etc. It just gives you a rough idea of the performance differential.
Parting thought

Photo by Sean Oulashin on Unsplash
And that was it!
We went from an external API specification to hosting our private LLM model in a GPU cloud.
Not bad!
LLMs are a powerful tool and more organisations will sooner or later see the need to host a private, specialised model.
In a production setting, we might have opted to go for a ready-to-use server, like vLLM, or a pay-as-you-go Llama
2 API, like RunPod’s.
Hopefully this article gave you the initial pointers to understand things and get started.
Until next time, excelsior!
Footnotes
- E.g. assuming the model has trained on English kids’ songs, then given the input “Mary had a little”, it would likely predict “ lamb, little lamb, little lamb” as the next few tokens.
- In essence chatting with an LLM is the equivalent of asking the question “Given all these previous conversations between the human and the LLM, what would you say next?”.
- Add a dummy
OpenAI API keyin the corresponding bottom-left field to enable the interface.
- Initially by mistake, but later as a deliberate choice.
- You can download any other GGML quantised Llama-compatible model, with any different quantisation, like Alpaca, Llama 2,…(e.g. a small list here). HuggingFace is a great starting point to search for GGML models.
- You may need to wipe out your local cluster first with
tilt down --delete-namespaces. -
I have chosen to deploy to RunPod for ease of use alone. This is not a recommendation nor is there any affiliation with RunPod.