

Neo4J is a multi-featured graph database, able to store billions of items. This brings up an interesting question: how much space will it take on disk?
Background
A Neo4J database is composed of (or better, stores) the following discreet data items on disk
- nodes
- relationships
- properties string values are stored separately in 128 byte chunks
- Lucene indexes over properties
- other stuff: house-keeping files, logs,…
I will ignore the size of all other stuff and just focus on how the data itself affects disk consumption.
It is important to note than in a cluster setup all nodes contain a complete copy of the data.
Overheads
Despite Neo’s great documentation, there is no central reference for the overheads and disk sizes. This is understandable to a degree as this is something internal and not a published contract. However, it is still a little bit annoying as one has to go in various locations to find bits and pieces
The following table gives an overview of the various items
| Item type | Size (in bytes) | Comments |
|---|---|---|
| Node | 15 | Per node instance |
| Relationship | 34 | Per relationship |
| Property | 41 | Each property value, including strings |
| String value | 128 | Strings take up whole blocks of 128b |
| Indexed property | 1/3 * AVG(X) | Each index entry is approximately 1/3 of the average property value size |
Example calculation
Let’s give an example, to illustrate how the numbers above come into play.
Let’s assume that we have a Neo4J database with the following 3 node instances (JSON representation)
1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"labels": [ "User", "Employee" ],
"properties":
{
"active":true,
"emailAddress":"test.foo@baz.com",
"employeeId":"1333",
"employeeType":"Permanent",
"firstName":"Test",
"fullName":"Test Foo",
"lastName":"Foo",
"telephoneNumber": 1234,
"usCitizen": true,
"userName":"foo"
},
"indexedProperties": ["employeeId", "userName", "lastName"]
}
2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"labels": [ "User", "Employee" ],
"properties":
{
"active":true,
"emailAddress":"bar@rbs.com",
"employeeId":"1444",
"employeeType":"Permanent",
"firstName":"Bar",
"fullName":"Bar Foo",
"lastName":"Foo",
"telephoneNumber": 4321,
"usCitizen": false,
"userName":"foo"
},
"indexedProperties": ["employeeId", "userName", "lastName"]
}
3)
1
2
3
4
5
6
7
8
9
10
11
{
"labels":["CostCentre"],
"properties":
{
"active":true,
"code":"id36123L2",
"level":2,
"name":"GALT FUND LLC"
},
"indexedProperties": ["code", "name"]
}
There are also 2 relationships with no properties attached to them
1
2
(1)-[MANAGER_OF]->(2)
(2)-[WORKS_FOR]->(3)
So for this tiny dataset we have
- 3 node instances
- 2 relationship instances
- 24 property “instances” (or better individual property values)
- …16 of which are string values
- 8 index entries
| Item type | Multiplied | Result (in bytes) |
|---|---|---|
| Node | 3 * 15 | 45 |
| Relationship | 2 * 34 | 68 |
| Property | 24 * 41 | 984 |
| String value | 16 * 128 | 2048 (all values are small so only one 120b chunk required) |
| Indexed property | 8 * 1.5 | 12 (average value length is ~4 bytes and Lucene calculations assume 1/3 of that per entry) |
| Total | 3157 |
So, the Neo4J database folder storing our model, will be around 3Kb on disk (provided we ignore logs and other housekeeping files)
A calculation template
Let’s consider the following example model to store in Neo4J.
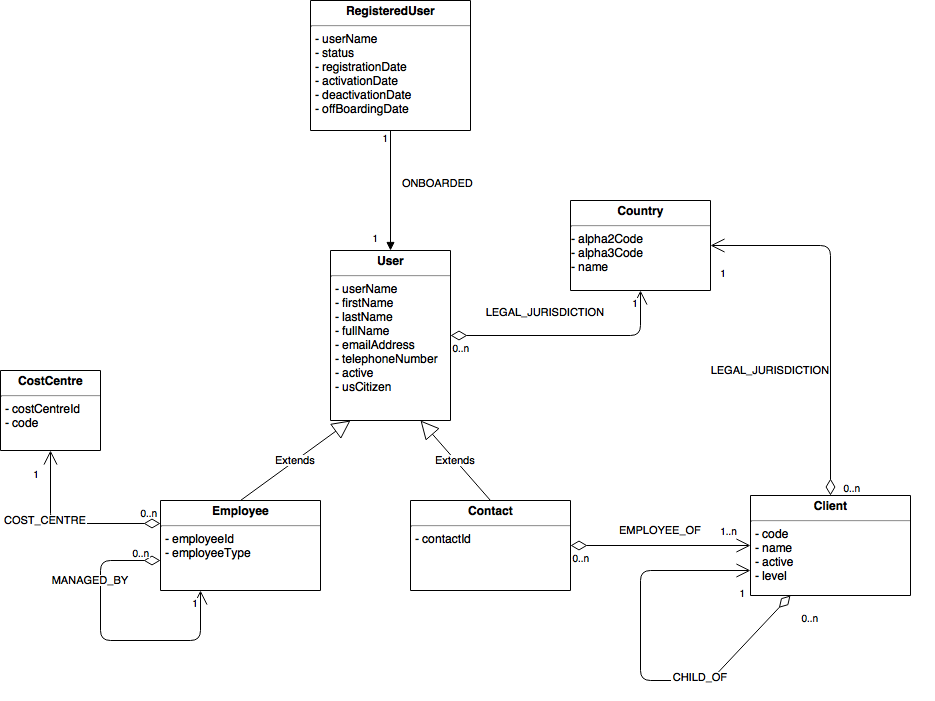
To make things simple, we can choose to implement relational inheritance (in this case User with Employee and Contact) by simply collapsing and adding additional labels.
So an employee node will have 2 labels:User and Employee.
We should know (or at least guesstimate) the following
- how many and what type of properties each class will have
- how many instances of each class (or better, node type) we will have
- how many other nodes each one is connected to on average
Once we have this information, we can create an Excel similar to the following
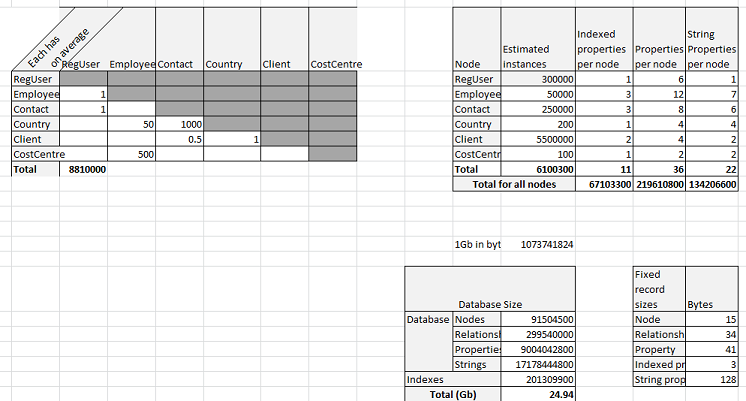
The right table captures how many nodes of each type we have along with the properties per node.
The left table calculates the number of relationships in total based on the averages.
So, for example, each Country has on average 50 Employees and each Client has 0.5 Contacts (because we know we have a lot of empty/unused Client entries).
These figures are then summed to calculate the final DB footprint.
You can download the Excel file from this link and use it as a basis for your own calculations. The file contains a VB macro, which recalculates the totals, when you update any cell.
In case you need to add/remove lines to the tables because your model is bigger/smaller, you will need to edit this Macro.
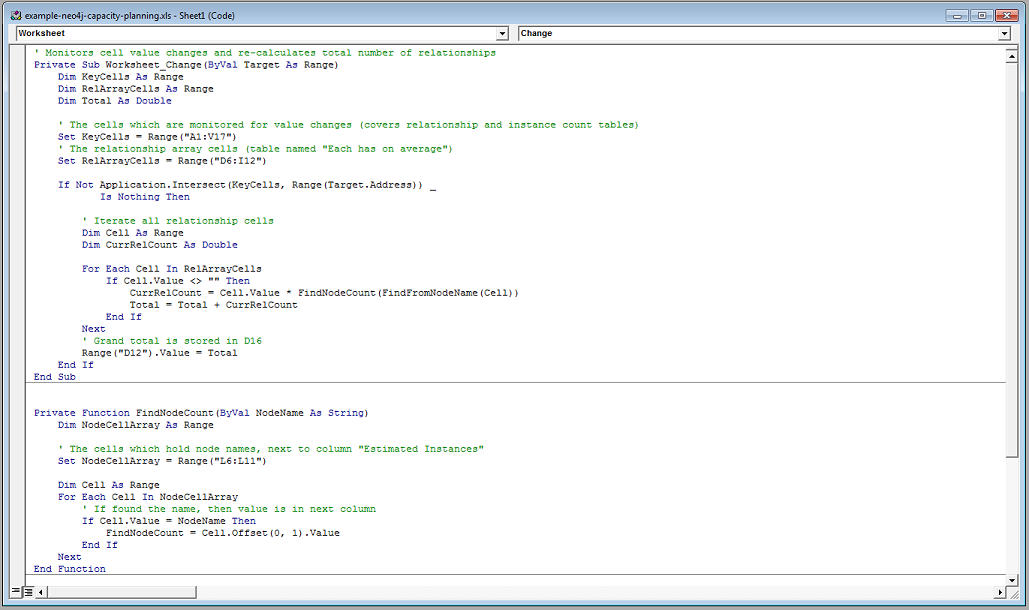
There might be a more elegant way to create this Excel, but I never said I was an Excel guru ;-) You comments and suggestions are welcome.
I hope you find it useful.